- ALL COMPUTER, ELECTRONICS AND MECHANICAL COURSES AVAILABLE…. PROJECT GUIDANCE SINCE 2004. FOR FURTHER DETAILS CALL 9443117328
Projects > ELECTRONICS > 2017 > IEEE > DIGITAL IMAGE PROCESSING
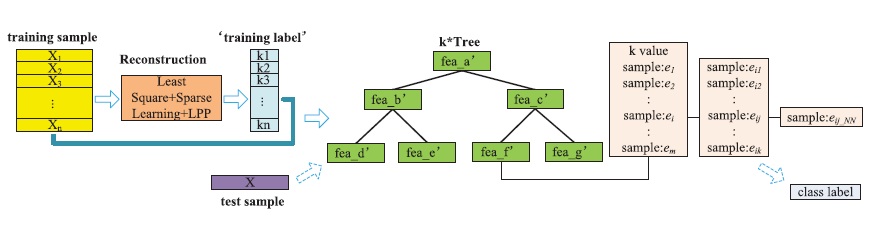
k nearest neighbor (kNN) method is a popular classification method in data mining and statistics because of its simple implementation and significant classification performance. However, it is impractical for traditional kNN methods to assign a fixed k value (even though set by experts) to all test samples. Previous solutions assign different k values to different test samples by the cross validation method but are usually time consuming. This paper proposes a kTree method to learn different optimal k values for different test/new samples, by involving a training stage in the kNN classification. Specifically, in the training stage, kTree method first learns optimal k values for all training samples by a new sparse reconstruction model, and then constructs a decision tree (namely, kTree) using training samples and the learned optimal k values. In the test stage, the kTree fast outputs the optimal k value for each test sample, and then, the kNN classification can be conducted using the learned optimal k value and all training samples. As a result, the proposed kTree method has a similar running cost but higher classification accuracy, compared with traditional kNN methods, which assign a fixed k value to all test samples. Moreover, the proposed kTree method needs less running cost but achieves similar classification accuracy, compared with the newly kNN methods, which assign different k values to different test samples. This paper further proposes an improvement version of kTree method (namely, k*Tree method) to speed its test stage by extra storing the information of the training samples in the leaf nodes of kTree, such as the training samples located in the leaf nodes, their kNNs, and the nearest neighbor of these kNNs. We call the resulting decision tree as k*Tree, which enables to conduct kNN classification using a subset of the training samples in the leaf nodes rather than all training samples used in the newly kNN methods. This actually reduces running cost of test stage.
Support Vector Machine, Nearest Neighbor Algorithm, Robust Sparse Coding.
In this paper, we first propose a kTree method for fast learning an optimal-k-value for each test sample, by adding a training stage into the traditional kNN method and thus outputting a training model, i.e., building a decision tree (namely, kTree) to predict the optimal-k-values for all test samples. Specifically, in the training stage, we first propose to reconstruct each training sample by all training samples via designing a sparse-based reconstruction model, which outputs an optimal-k-value for each training sample. We then construct a decision tree using training samples and their corresponding optimal-k-values, i.e., regarding the learned optimal-k-value of each training sample as the label. The training stage is offline and each leaf node stores an optimal-k-value in the constructed kTree. In the test stage, given a test sample, we first search for the constructed kTree (i.e., the learning model) from the root node to a leaf node, whose optimal-k-value is assigned to this test sample so that using traditional kNN classification to assign it with a label by the majority rule. The key idea of our proposed methods is to design a training stage for reducing the running cost of test stage and improving the classification performance.
Proposed kTree Method
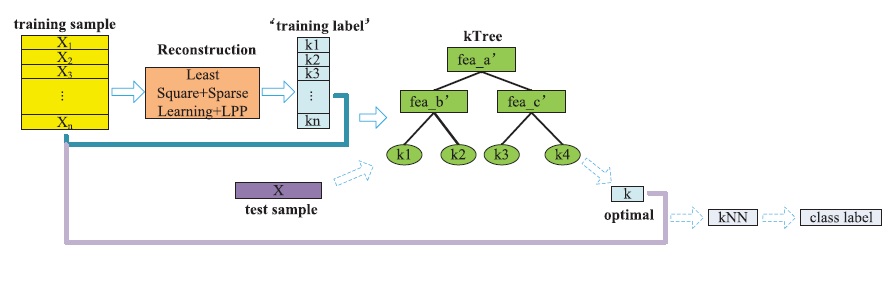
Proposed k*Tree Method