- ALL COMPUTER, ELECTRONICS AND MECHANICAL COURSES AVAILABLE…. PROJECT GUIDANCE SINCE 2004. FOR FURTHER DETAILS CALL 9443117328
Projects > ELECTRONICS > 2017 > IEEE > VLSI
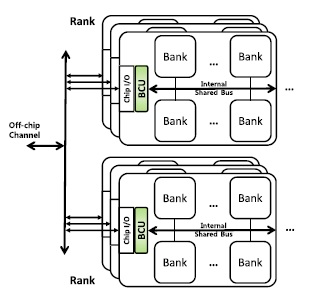
We propose an approach called buffered compares, a less-invasive processing-in-memory solution that can be used with existing processor memory interfaces such as DDR3/4 with minimal changes. The approach is based on the observation that multibank architecture, a key feature of modern main memory DRAM devices, can be used to provide huge internal bandwidth without any major modification. We place a small buffer and a simple ALU per bank, define a set of new DRAM commands to fill the buffer and feed data to the ALU, and return the result for a set of commands (not for each command) to the host memory controller. By exploiting the under-utilized internal bandwidth using ‘compare-n-op’ operations, which are frequently used in various applications, we not only reduce the amount of energy inefficient processor–memory communication, but also accelerate the computation of big data processing applications by utilizing parallelism of the buffered compare units in DRAM banks. We present two versions of buffered compare architecture–full scale architecture and reduced architecture–in trade of performance and energy.
Assembly algorithm, complementary bit-cell architecture.
In this paper, we have proposed buffered compares, which puts lightweight logic inside DRAM banks to perform frequently recurring patterns of many workloads efficiently. Our key contributions are as follows. We identify that abundant internal bandwidth unused in modern DRAM architecture provides the opportunity to exploit this extra bandwidth with NDP. We propose buffered compare architecture that performs compare-n-op operations inside DRAM to provide parallelism and off-chip bandwidth savings with lightweight logic. We suggest a way to solve the system integration issues of buffered compare, including programming model, coherence, memory protection, and data placement. We investigate six workloads that utilize buffered compares to enhance system performance and energy efficiency. We also present a detailed circuit-level analysis of buffered compare units (BCUs) on performance, power, and area overheads.
Buffered Compare Architecture
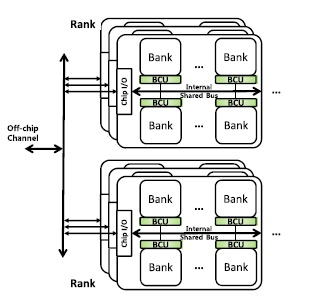
BC-Light Architecture